“You’d be surprised how much gray matter is dedicated to the analysis of facial imagery. Shame to waste it on anything as … counterintuitive as residual plots or contingency tables.”
Watts, Peter. Blindsight (Firefall) (p. 337). Tom Doherty Associates. Kindle Edition.
Before reading any further try to find a pattern in the video. Is eye size related to the hair color or maybe the older the face the wider the nose?
The Experiment
Recently Nvidia published the Stylegan3 so I decided it is past time to close my tabs with Stylegan2. Peter Watts theorized that our brains are more accustomed to distinguishing patterns in faces than in boring and artificial graphs and he proposed an interface for view data
“Skull diameter scales to total mass. Mandible length scales to EM transparency at one angstrom. One hundred thirteen facial dimensions, each presenting a different variable. Principle-component combinations present as multifeature aspect ratios.”
Watts, Peter. Blindsight (Firefall) (p. 337). Tom Doherty Associates. Kindle Edition.
So I decided to look into that. Let’s say we have some data where Y is linearly dependent on X (Y = aX + b). First, let’s add some noise and get something like this
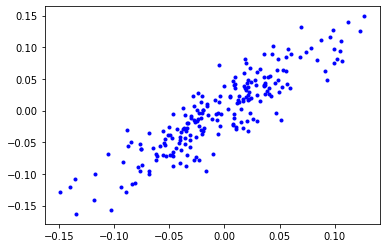
To make the task a little bit more interesting let’s add 4 more dimensions to X. However to make the experiment a little easier to understand let’s have Y dependent only on one of X 5 dimensions.
X, y = make_regression(
n_samples=212, n_features=5, n_informative = 1, random_state=0, noise=8.0
)
Now we can visualize this data using a human face.
First, let’s get a face. Our centre of coordinates. In Blindsight the interface was optimized for a vampire I went with something a little bit more pedestrian.

Now let’s say we have 6 different axes (about drawbacks of this approach later) we can use to “morph” the image.
- age
- smile
- gender
- eye size
- hair black
- hair red
So we use Y for our smile axis, informative X as our age axis and all uninformative X values for other axes.
Now for every point of the data, we can generate an image.
We can make the task of finding patterns a little bit more interesting by adding outliers - data points that do not obey the original pattern.
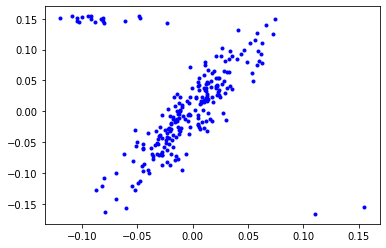
Repeating the previous process we get
Or alternatively, we can make the task easier and sort the data points by Y
Problems with the approach
This little experiment can hardly be called scientific.
- The basic approach based on latent directions (smile, age, etc.) for Stylegan is flawed because the vectors (directions) are imperfect and not independent at all (it is pretty obvious that going along the age direction we also get someone with a more pronounced Asian ethnicity and more pronounced “eye asymmetry”).
- The mind’s ability to find patterns has to be measured somehow and this approach compared with other forms of multidimensional data representation.
- I am using vectors derived for Stylegan 2 against Stylegan2-ada network (here are videos for Stylegan network (https://vimeo.com/647172530, https://vimeo.com/647164228)).
But a straight comparison of data presented as a series of faces with data presented as a huge table does give some credence to the idea of “human face-based data visualization”.
The Prototype
Regrettably, I do not have access to GPU enabled server, so for now let’s just give a rough sketch of what an app for further experimentations might look like.
- I want a web app where anyone can upload a medium-sized dataset to visualize using Stylegan.
- The app should allow the user to specify what columns should correspond to what latent vectors.
- Additionally the app should allow the user to forgo the usage of the latent vectors and project the data into the latent space directly.
- The user should be able to specify basic transformations for every column (scaling, log, shift).
- The user should be able to view the result either as a video or a series of images.
Looks straightforward enough. I hope to come back to this idea after some experiment with Stylegan 3.